
Denoising diffusion models have shown great promise in human motion synthesis conditioned on natural language descriptions. However, it remains a challenge to integrate spatial constraints, such as pre-defined motion trajectories and obstacles, which is essential for bridging the gap between isolated human motion and its surrounding environment.
To address this issue, we propose Guided Motion Diffusion (GMD), a method that incorporates spatial constraints into the motion generation process. Specifically, we propose an effective feature projection scheme that largely enhances the coherency between spatial information and local poses. Together with a new imputation formulation, the generated motion can reliably conform to spatial constraints such as global motion trajectories.
Furthermore, given sparse spatial constraints (e.g. sparse keyframes), we introduce a new dense guidance approach that utilizes the denoiser of diffusion models to turn a sparse signal into denser signals, effectively guiding the generation motion to the given constraints.
The extensive experiments justify the development of GMD, which achieves a significant improvement over state-of-the-art methods in text-based motion generation while being able to control the synthesized motions with spatial constraints.
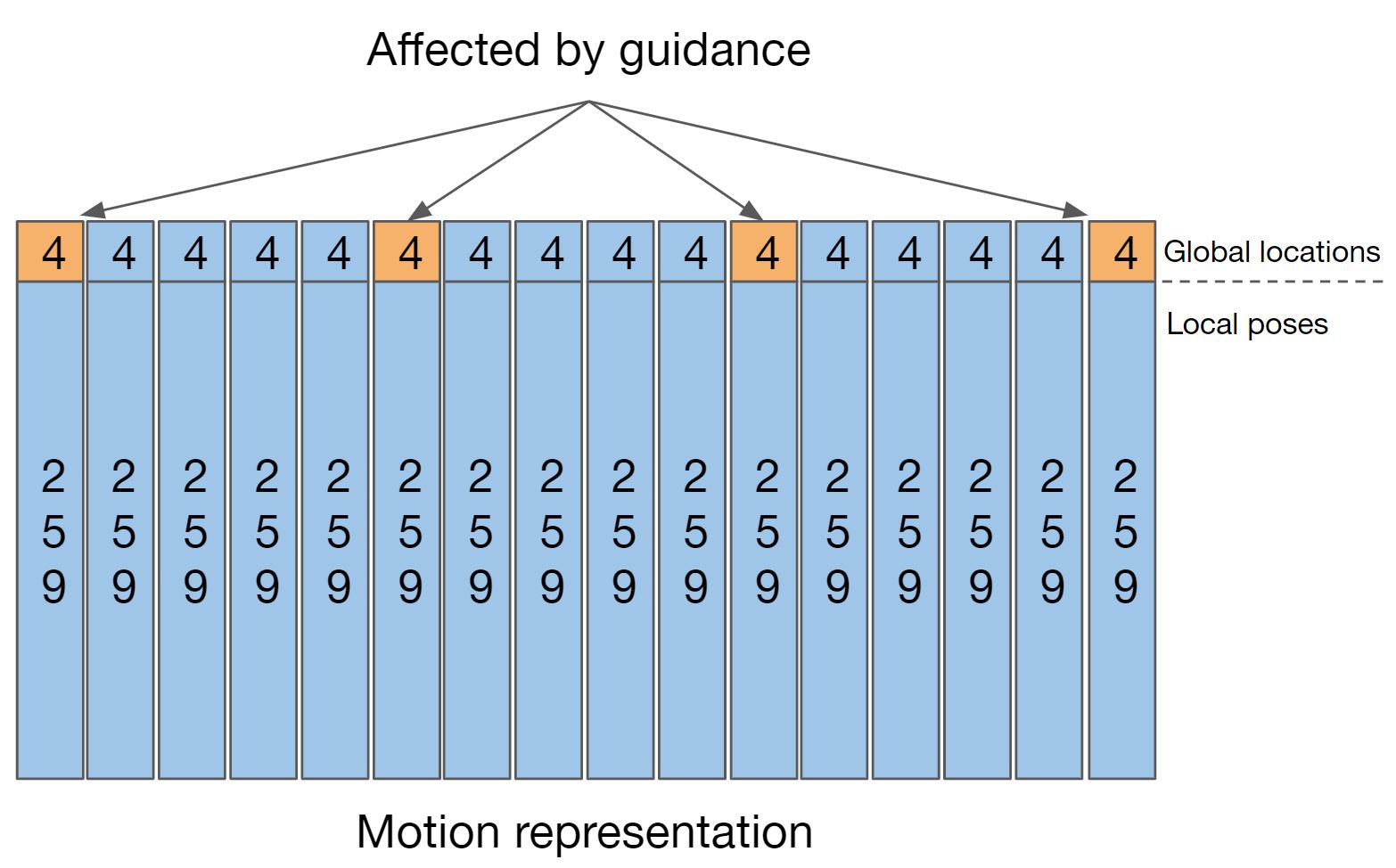
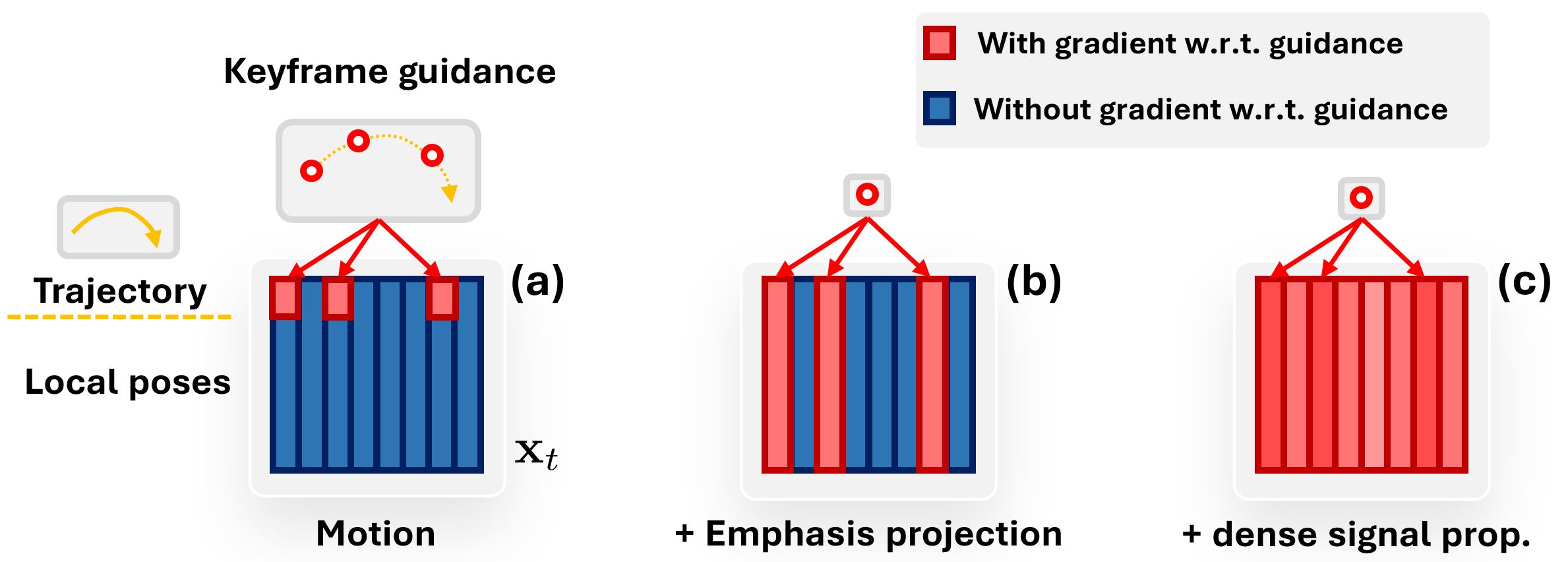
In GMD, we tackle the problem of spatially conditioned motion generation using a two-staged pipeline (a) The optional first stage generates a trajectory given spatial conditioning. Then, the second stage synthesizes motions accroding to the trajectory. Our main contributions are (b) Emphasis projection, for better trajectory-motion coherence, and (c) Dense signal propagation, for a more controllable generation even under sparse guidance signal.
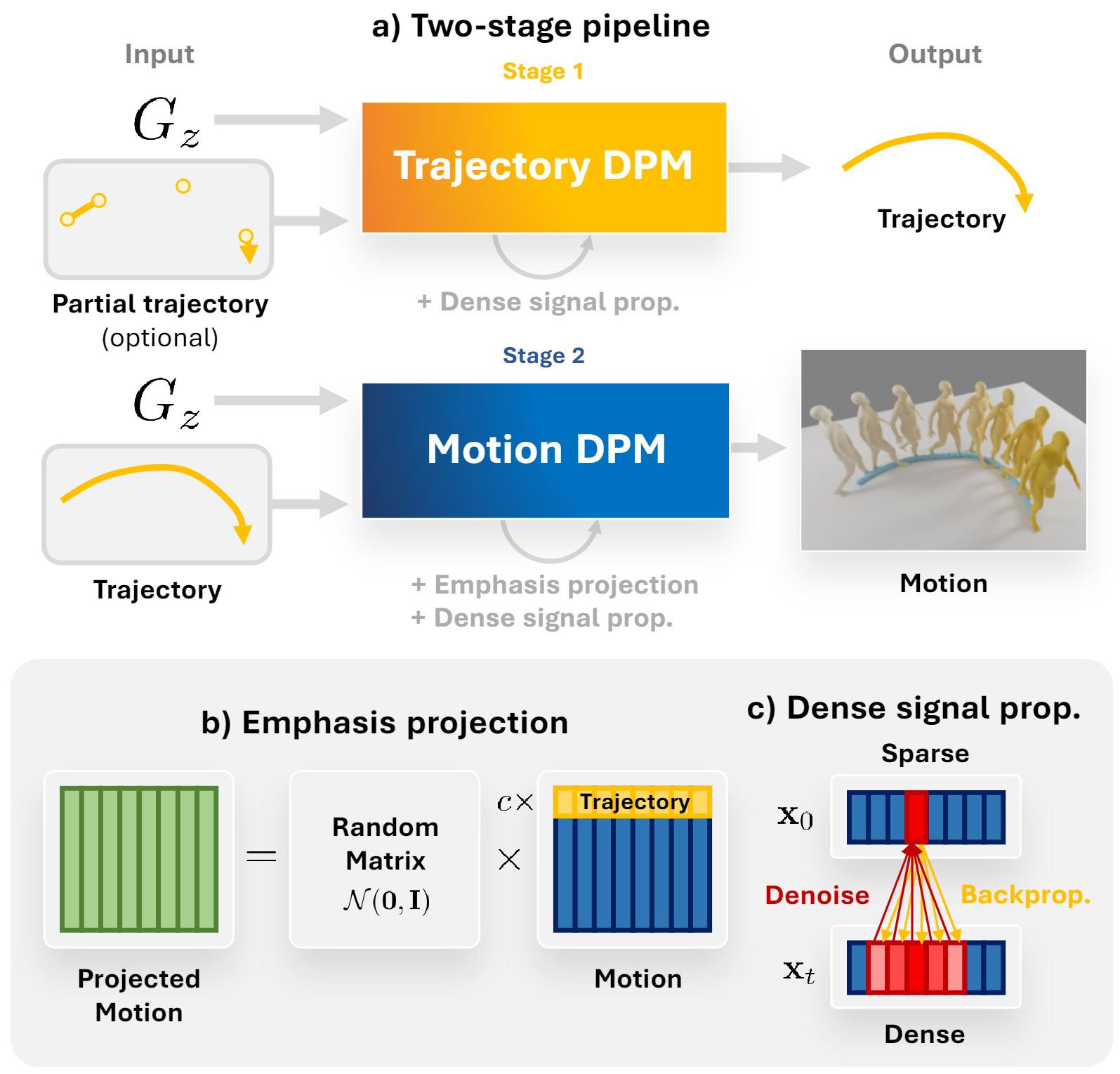
The most straightforward way of forcing the model to put more importance on the trajectory is to simply scale up its loss weight compared to other parts during training. Nevertheless, we found that loss manipulation is ineffective in this setting and also makes the training less stable. To achieve the same effect, we can scale up the value of the trajectory in the motion representation (multiply the values by c). But, doing so means the variance of each value in the motion vector will not be the same, which most diffusion models assume to be the case. The emphasis projection is then the next most straightforward solution for adjusting trajectory importance while taking these problems into account. It can be described as follows:
Our goal is to convert the sparse guidance signals that are defined on some keyframes to denser signals during denoising. As the spatial guidance can only be defined on the clean motion (X0) but we need gradients w.r.t. the noisy motion (Xt) to guide the motion at the denoising step t, we observe that
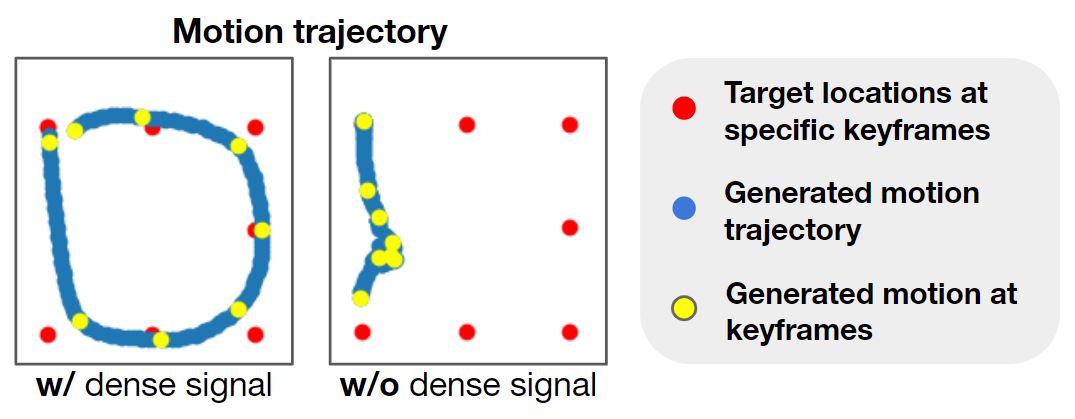
Generated motion trajectories, conditioned on target locations at given keyframes. Without dense signal propagation, the model ignores the target conditions
@inproceedings{karunratanakul2023gmd,
title={Guided Motion Diffusion for Controllable Human Motion Synthesis},
author={Karunratanakul, Korrawe and Preechakul, Konpat and Suwajanakorn, Supasorn and Tang, Siyu},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={2151--2162},
year={2023}
}